


































































La interacción humana con tecnologías disruptivas como, por ejemplo, la inteligencia artificial[1], es un hecho que tiene lugar cada vez con mayor frecuencia y en los más diversos ámbitos de nuestras vidas. Desde lo social y profesional, hasta en lo comercial, nos valemos de la inteligencia artificial para desenvolvernos a diario.
Por ello, y muy a pesar de ciertas resistencias —asociadas en ocasiones al temor hacia la discriminación de parte de algunos sistemas informáticos inteligentes[2]—, podremos coincidir en que este conjunto de técnicas y tecnologías llegó para quedarse, aportándonos un sinfín de herramientas cada vez más sofisticadas. Por caso, la creación de datos sintéticos que pueden servir para entrenar otros sistemas inteligentes[3].
Ahora bien, responder al interrogante relativo a si los datos sintéticos representan o no una posible solución a la reproducción de sesgos en los algoritmos requiere repasar —con los límites dados por estas breves líneas—, ciertas bases de comprensión.
Primero. ¿Qué es la inteligencia artificial[4]?
La noción de Inteligencia Artificial fue acuñada en 1956 por un grupo de investigadores —John McCarthy, Marvin L. Minsky, Nathaniel Rochester and Claude E. Shannon— que organizó el evento que luego sería reconocido como el que dió inicio al estudio de la Inteligencia Artificial: el workshop de verano llamado “Estudio de la Inteligencia Artificial”[5]. La idea de razonamiento humano artificial, a su vez, se remonta al trabajo del matemático Alan Turing[6], como también a los modelos matemáticos de las neuronas de McCulloch y Pitts.
Ahora bien, aún cuando cuenta con un largo recorrido —con sus veranos e inviernos—, lo cierto es que, a la fecha, no existe una definición de inteligencia artificial que sea universalmente aceptada[7]. Lo que encontramos, en todo caso, son diferentes conceptualizaciones según las distintas disciplinas que han abordado a la Inteligencia Artificial como objeto de estudio[8].
Aún así, desde una óptica general, la inteligencia artificial puede describirse como una disciplina que busca simular la inteligencia humana a través de un sistema informático. En otras palabras, lo que en general se intenta lograr es que estos sistemas nos brinden respuestas o propuestas rápidas, a partir de la simulación —mediante el uso de algoritmos— de procesos de razonamiento humano.
Por eso, más allá de lo complejo que puede resultar conceptualizar a la Inteligencia Artificial, en un sentido amplio se puede decir que se trata de máquinas capaces de aprender, razonar y actuar por sí mismas.
Dentro del universo de la Inteligencia Artificial, encontramos diferentes formas de entrenamiento de algoritmos. El empleo o selección de las diferentes técnicas y funcionalidades existentes dependerá siempre del objetivo creativo perseguido por sus desarrolladores.
En lo que al aprendizaje automático[9] —machine learning— refiere, y más aún con la variante del aprendizaje profundo —deep learning—, se requiere de datos que serán utilizados, especialmente, durante su etapa de entrenamiento.
Ello, se aclara, no implica sostener que todos los sistemas inteligentes demanden siempre una gran cantidad o volumen de datos, pues esta circunstancia dependerá también de los matices propios del objetivo perseguido.
Recordemos que la técnica de inteligencia artificial que se seleccione o que, en definitiva se aplique, no será más que un traje a medida. Es decir, elaborada para el caso en concreto u “objetivo-fin” buscado por quienes desarrollan el sistema.
Por lo tanto, si bien se requieren datos para entrenar modelos inteligentes de machine learning, no siempre será necesario disponer de un gran volumen de aquellos.
Segundo. ¿Qué implica el uso de datos?
Entrenar algoritmos mediante el uso de datos conlleva ciertos problemas cuando de datos personales se trata.
Por mencionar alguno: lo inherente a su disponibilidad —tanto de calidad como en cantidad—, encuentra su primer valladar en las regulaciones o limitaciones relativas a su protección como ser la privacidad de esos datos.
Cabe recordar por ello que los datos personales, presentes también en imágenes o videos, no son otra cosa que información de cualquier tipo referida a personas determinadas o determinables. Aquí, por tanto, se encuentran de las más variadas críticas asociadas a la captación, venta y tratamiento de datos personales sin el consentimiento.
Otro problema asociado al uso de datos personales —si se quiere el más importante— es que estos dejan huella y terminan por reflejar nuestros valores culturales y creencias sociales, por lo que su tratamiento requiere de especial formación y dedicación para evitar entrenar algoritmos que terminen reproduciendo estereotipos, sesgos y prejuicios humanos, lo que nos lleva al siguiente interrogante.
Tercero. ¿Qué se entiende por sesgos algorítmicos?
En un sentido técnico, se denomina sesgo algorítmico a las decisiones erradas propias de un sistema informático, tengan o no, consecuencias disvaliosas para las personas.
Y desde una perspectiva más cotidiana, se entiende que si esos errores del sistema provocan o son capaces de provocar un impacto desfavorable respecto de ciertas personas o grupos de personas, ello facilitará y dará paso a la discriminación algorítmica[10].
Esta última, se aclara, no es “creada” por la tecnología, ni puede ser atribuida a una técnica o funcionalidad en particular porque los sesgos algorítmicos tienen, como antecedente inmediato, a los errores sistemáticos o dispersos de los humanos[11] que, a su vez, se gestan y tienen lugar, en el proceso humano de toma de decisiones.
Es así que los sesgos algorítmicos se nutren, necesariamente, del sistema de valores que provienen de los errores-humanos, ya que al reflejarse esos errores en los datos, los reproducen y con ello pueden provocar desigualdades existentes en el mundo físico. De allí la enorme importancia que cabe dar a la intervención humana adecuada en el diseño, desarrollo, despliegue y control posterior de los sistemas de Inteligencia Artificial.
Ahora bien, como se anticipó, desde hace algún tiempo han entrado en escena diferentes propuestas destinadas a crear datos sintéticos para diferentes fines[12].
Cuarto. ¿Qué son los datos sintéticos?
Los datos sintéticos son datos artificiales creados por un sistema informático con el fin de sustituir datos reales[13]. En otras palabras, son datos que se crean en el mundo digital en vez de recolectarse o medirse en el mundo real.
Para ello, se diseñan sistemas inteligentes que se valen de datos reales que les sirven de base y son capaces de impulsar, matemática o estadísticamente, la creación de nuevos datos ficticios o sintéticos. Es decir, que no se han recopilado a partir de la interacción con personas reales. Por ejemplo, una imagen artificial que no ha sido tomada con una cámara de fotos, sino que ha sido creada por un algoritmo:

A close-up photo of a teddy bear in a laboratory doing an experiment, a little crazy, cute, cuddly, wearing scientist clothes
El objetivo perseguido parece ser claro: frente a la indisponibilidad o poca disponibilidad de datos —sea por su protección, por ausencia o por insuficiencia de datos reales de calidad—, impulsar datos sintéticos puede resultar muy útil para entrenar modelos inteligentes. Incluso, diferentes empresas han desarrollado plataformas que no tienen por objeto entrenamiento alguno, sino la simple interacción con el usuario que los utiliza, también, para diferentes fines, sean estos recreativos, particulares, sociales, laborales, etc[14].
Ahora bien, estas utilidades presentan matices, al menos en lo que a sesgos informáticos refiere, que deben ser consideradas.
Desde luego que enfrentar el entrenamiento de un sistema con datos reales sesgados dificulta la tarea o el objetivo perseguido y, por tanto, puede ser una solución utilizar una mínima cantidad de éstos —previamente seleccionados— con el objetivo de impulsar datos sintéticos de calidad.
Sin embargo, ya sea que se utilicen datos reales o bien, sintéticos, el mar de fondo sigue siendo nuestra cultura humana. Y esta circunstancia que veremos, anticipa la respuesta al siguiente interrogante.
Quinto. ¿Pueden los datos sintéticos mitigar el problema de la reproducción de sesgos en los algoritmos?
Como se adelantó, muchos de los errores sistemáticos que reproducen los algoritmos encuentran como antecedente inmediato los valores, concepciones y creencias culturales que se reflejan en los datos del mundo real de los que se nutren los sistemas, pero también de los que están presentes en las personas que toman decisiones con relación a ellos.
En otras palabras, las creencias, estereotipos y prejuicios no son ajenos a los datos, sean estos reales o sintéticos. Y no son ajenos a los datos sintéticos porque, en definitiva, la creación de un dato por un algoritmo siempre conlleva la toma de decisiones humanas o implica el reflejo, matemático o estadístico, de datos obtenidos del mundo real.
Es a través de las personas que se incorporan datos reales que servirán de semilla o puntapié inicial para el impulso de datos sintéticos, a la vez que serán también éstas quienes participarán de la validación de los aciertos durante la etapa de entrenamiento y, en general durante todo el ciclo de vida del sistema. Ni que hablar si estos sistemas permiten generar un resultado al combinarse con o al integrar un dato del mundo real —por ejemplo, DALL-E 2 permite ahora editar imágenes de rostros humanos reales—[15].
Ante este escenario, si las personas humanas que forman parte de las decisiones inherentes al sistema no tienen la debida formación —por caso en diversidad y género— terminarán validando datos sintéticos que reproduzcan errores, estereotipos, prejuicios y valores culturales humanos que no son aceptables.
Esto sucede, a modo de ejemplo, con sistemas de generación de imágenes a partir de lenguaje natural, aún a pesar de los esfuerzos por abordar la problemática[16]:
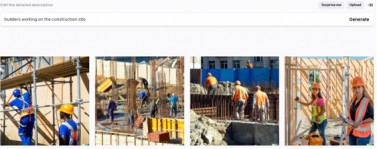
Entrada: builders working on the construction site (constructores trabajando en el sitio de construcción) / Autor: DALL -E 2

Entrada: close up photo of a tired doctor, working a lot during the pandemic, with burn out syndrome, pensive, reflecting on hoy difficult his job is / Autor: DALL -E 2
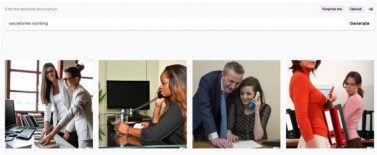
Entrada: secretaries working / Autor: DALL -E 2
Conclusión
Allí donde hay juicio humano, hay errores y, ya sea que las decisiones humanas tengan lugar en el proceso creativo o en el posterior desarrollo del sistema informático para impulsar datos sintéticos, debemos tomar conciencia de que es necesario interactuar con personas humanas formadas —como se dijo en diversidad y género—, para mitigar reproducción de esos errores en los datos sintéticos de los que luego se valdrá el sistema informático.
Siempre sin perder de vista que, sea que para el entrenamiento de un sistema se utilicen datos sintéticos o datos reales, es en las personas humanas en quienes recae la responsabilidad de velar por el adecuado tratamiento de aquellos.
Citas
(*) Jueza integrante de Sala IV, Cámara CAyTy RC de la CABA. Máster en Prevención contra la violencia de género, Mención Honorífica por la Universidad de Salamanca España. Máster en Administración de Justicia por laUniversità degli Studi di Roma "Unitelma Sapienza", Italia.
(**) Relatora del Superior Tribunal de Justicia de la Provincia de Tierra del Fuego AeIAS. Magíster en Derecho Administrativo (Universidad Austral, Diploma de Honor). Doctorando en Cs. Jurídicas (UCA).
[1] Hao, (2019) La inteligencia artificial está cada vez más presente en más productos y servicios. Pero… ¿Qué es la IA exactamente? Puede que le parezca una pregunta tonta, pero la respuesta es algo complicada https://www.technologyreview.es/s/10738/como-saber-si-esta-usando-una-ia-descubralo-con-este-grafico
[accedido 6/10/22].
[2] Desde sistemas de vigilancia por reconocimiento facial hasta otros implementados para decidir sobre la libertad condicional de presos, existen numerosos ejemplos de modelo inteligentes que han presentado errores hacia personas o grupos sea por razones etnia, género, entre otros.
[3] “Datos sintéticos, un recurso vital para la Inteligencia Artificial”, en https://www.arsys.es/blog/datos-sinteticos#:~:text=Los%20datos%20sint%C3%A9ticos%20es%20informaci%C3%B3n,para%20la%20consecuci%C3%B3n%20de%20fines [accedido el 6/10/2022].
[4] A diferencia de lo que ocurre con otras tecnologías, se ha visto la necesidad de regular ciertos aspectos de esta y marcar estándares de funcionamiento. Es el caso de la Unión Europea (2020) y la Organización para la Cooperación y Desarrollo Económico (2019), Primer acuerdo mundial sobre la ética de la inteligencia artificial | Noticias ONU [accedifo el 6/10/22] https://www.europarl.europa.eu/doceo/document/TA-9-2022-0140_ES.html [accedido el 6/10/22]
[5] Nick BOSTROM, “The Ethics of Artificial Intelligence”, Draft for Cambridge Handbook of Artificial Intelligence, Londres, 2011, en https://www.nickbostrom.com/ethics/artificial-intelligence.pdf [accedido el 4/3/2022], p. 2. También: COMISIÓN MUNDIAL DE ÉTICA DEL CONOCIMIENTO CIENTÍFICO Y LA TECNOLOGÍA, “Preliminary Study on…”, p. 5.
[6] https://www.cultura.gob.ar/alan-turing-el-padre-de-la-inteligencia-artificial-9162/#:~:text=Fue%20famoso%20por%20descifrar%20el,108%20a%C3%B1os%20de%20su%20nacimiento.[accedido el 6/10/22]
[7] Ampliar en Sofia SAMOILI, Montserrat LÓPEZ COBO, Blajob DELIPETREV, Fernando MARTÍNEZ-PLUMED, Emilia GÓMEZ y Giuditta DE PRATO, AI Watch. Defining Artificial Intelligence 2.0: Towards an operational definition and taxonomy for the AI landscape, Publications Office of the European Union, Luxembourg, 2021, en https://publications.jrc.ec.europa.eu/repository/handle/JRC118163 [accedido el 30/4/2022.]
[8] COMISIÓN MUNDIAL DE ÉTICA DEL CONOCIMIENTO CIENTÍFICO Y LA TECNOLOGÍA, “Preliminary Study on the Ethics of Artificial Intelligence”, Paris, UNESCO, 26 de febrero de 2019, en https://unesdoc.unesco.org/ark:/48223/pf0000367823 [accedido el 4/4/2022], p. 3.
[9] TechTarget (2017) Aprendizaje automático (machine learning)
https://searchdatacenter.techtarget.com/es/definicion/Aprendizaje-automatico-machine-learning[accedido el 6/10/22]
[10] https://ialab.com.ar/wp-content/uploads/2022/03/Sesgos-algoritmicos-de-genero.pdf [accedido el 6/10/22]
[11] DANIEL Kahneman y otros, “Ruido, Una Falla en el juicio humano”, pág. 13 y ss, Ed. Penguin Random House Grupo Editorial, Arg. 2021.
[12] DALL-E 2 de OpenAI, ver https://openai.com/dall-e-2/ [accedido el 14/9/2022]. Midjourney de la firma con el mismo nombre, ver https://midjourney.gitbook.io/docs/user-manual [accedido el 14/9/2022] o StabilityAI, ver https://stability.ai/blog/stable-diffusion-public-release [accedido el 14/9/2022]. Otro ejemplo,un modelo de inteligencia artificial para un fabricante de automóviles global con datos sintéticos https://hitechglitz.com/spanish/el-poder-de-las-imagenes-sinteticas-para-entrenar-modelos-de-ia/ [accedido el 6/10/22].
[13] ¿Qué son los datos sintéticos? https://la.blogs.nvidia.com/2021/07/20/que-son-los-datos-sinteticos/ [accedido el 6/10/2022] y https://www.arsys.es/blog/datos-sinteticos#:~:text=Los%20datos%20sint%C3%A9ticos%20es%20informaci%C3%B3n,para%20la%20consecuci%C3%B3n%20de%20fines.[accedido el 6/10/22].
[14] Por ejemplo DALL-E 2 de OpenAI, ver https://openai.com/dall-e-2/ [accedido el 14/9/2022]. Midjourney de la firma con el mismo nombre, ver https://midjourney.gitbook.io/docs/user-manual [accedido el 14/9/2022] o StabilityAI, ver https://stability.ai/blog/stable-diffusion-public-release [accedido el 14/9/2022].
[15] “DALL-E Users Can Now Upload and Edit Real Human Faces. What Could Possibly Go Wrong?”, en https://gizmodo.com/dall-e-ai-openai-deep-fakes-image-generators-1849557604 [accedido el 6/10/2022].
[16] “Dall-e 2: Pretraining mitigations”, en https://openai.com/blog/dall-e-2-pre-training-mitigations/ [accedido el 10/9/2022].
Opinión


opinión
ver todosAGUIRRE SARAVIA & GEBHARDT ABOGADOS
PASSBA
Kabas & Martorell
detrás del traje
Nos apoyan